~ 11 min read
Automating DevRel Conference CFP Evaluation with AI Agents: A Complete Guide with the Mastra AI Framework

As someone deeply involved in the tech community and conference organizing, I’ve personally experienced the overwhelming burden of reviewing hundreds of Call for Papers (CFP) submissions. Each conference season, I’d find myself drowning in spreadsheets, trying to maintain consistency while evaluating diverse topics, speaker backgrounds, and technical depth. The manual process was not only time-consuming but also prone to human bias and fatigue.
That’s when I decided to build something new: an AI-powered CFP evaluation system using Mastra AI agents. This isn’t just another automation tool—it’s a comprehensive solution that maintains the human judgment quality while scaling to handle hundreds of submissions efficiently. This work is aimed to be an initial proposal for conference organizers and DevRel teams looking to streamline their CFP review process and was part of the Mastra AI Hackathon in August 2025.
following is my journey through building an AI-powered system that proposes an agentic AI workflow for conference CFP committee
Meet My Mastra AI CFP Evaluation Agent
I built this system around the Mastra AI framework, leveraging TypeScript for type safety and SQLite for reliable persistence. The core innovation lies in transforming subjective evaluation criteria into structured, AI-powered assessments that provide both numerical scores and detailed justifications.
Here’s a quick overview of the AI agent at work:
What My AI Agent System Actually Does
My CFP evaluation agent doesn’t just score submissions, but also provides comprehensive analysis across multiple dimensions:
- Automated Evaluation: AI agents analyze each session proposal across 6 distinct criteria
- Smart Scoring: 1-5 scale scoring with detailed justifications for transparency
- Batch Processing: Handles hundreds of submissions using queue-based processing
- Resume Capability: Never loses progress during interruptions (learned this the hard way during API rate limits)
- Dual Workflow System: Evaluates both session content AND speaker profiles
- Export Flexibility: Multiple output formats for integration with existing tools
The technology stack I chose reflects my priorities for reliability and developer experience:
- Mastra AI for agent orchestration and workflow management
- TypeScript for type safety and maintainable code
- SQLite for zero-dependency persistence
- fastq for controlled concurrent processing
- Playwright MCP for web scraping speaker profiles
Understanding My 6-Criteria Evaluation Framework
After participating in multiple conference CFP committees, I want to propose an initial six key criteria that would contribute to a fair prediction of session quality and audience satisfaction:
1. Title Evaluation (1-5 Scale)
The title is your first impression—I evaluate clarity, engagement potential, and how well it describes the actual content. A great title like “Building Resilient Microservices: Lessons from 1000 Production Failures” immediately tells you what to expect.
2. Description Assessment (1-5 Scale)
This is where I dig deep into how well the speaker explains their content, identifies the target audience, and articulates the value proposition. I look for specific learning outcomes and clear structure.
3. Key Takeaways Analysis (1-5 Scale)
I evaluate the actionability and concrete value of what attendees will learn. Vague takeaways like “understand microservices better” score low, while specific ones like “implement circuit breaker patterns using Node.js” score high.
4. Technical Depth Review (1-5 Scale)
This assesses the sophistication and depth of technical content. I evaluate whether the session provides surface-level overview or deep, implementable insights.
5. Relevance Scoring (1-5 Scale)
How well does this session align with the conference theme and target audience? A blockchain talk might score low at a JavaScript conference unless it specifically focuses on JavaScript blockchain development.
6. Previous Presentation History (1-5 Scale)
I evaluate whether the speaker has given this talk before and how that impacts the content freshness and delivery quality.
Total Score Range: 6-30 points, giving me a clear ranking mechanism across all submissions.
Architecture Deep Dive: How I Built It
Core Components
I designed the system with four main components, each handling specific responsibilities:
-
1. Main Application Controller (
src/app.ts) - This orchestrates the entire evaluation process using fastq for queue management. I chose to process one session at a time during testing, but it’s configurable for production scaling. -
2. Database Service (
src/services/database/index.ts) - My SQLite-based persistence layer handles all CRUD operations with proper status tracking. The service includes robust path resolution to handle Mastra’s unique execution environment—a critical detail I discovered during development. -
3. CFP Evaluation Agent (
src/mastra/agents/cfp-evaluation-agent.ts) - The AI brain of the system that evaluates session content using structured prompts and returns consistent scoring with justifications. -
4. Workflow Engine (
src/mastra/workflows/cfp-evaluation-workflow.ts) - This orchestrates the entire evaluation process, managing data flow between components and handling both session and speaker assessments.
Data Flow Architecture
The system follows a clear pipeline that I designed for reliability and resumability:
Sessionize JSON → SQLite Database → Processing Queue → AI Workflow → Evaluation Results → Export OptionsEach step is independent and recoverable, ensuring that API failures or interruptions don’t lose progress making it easy to keep the process on track when processing hundreds of submissions.
Database Schema Design
I implemented a normalized schema that supports complex relationships while maintaining performance:
Sessions Table: Stores session data with individual score fields for efficient querying Speakers Table: Normalized speaker information with proper relationships Session-Speakers Junction: Many-to-many relationships between sessions and speakers Speaker Evaluations: Separate evaluation tracking with UUID-based versioning
This design eliminates data redundancy while enabling sophisticated queries for analysis.
How to Get Started: A Step-by-Step Guide
Getting this AI agent running takes less than 5 minutes:
# Clone and install dependencies
git clone https://github.com/lirantal/devrel-cfp-committee
cd devrel-cfp-committee
npm install
# Initialize database with sample data
npm run db:seed
# Process CFP submissions
npm run process-cfp
# Start interactive playground
npm run devThe seeding process loads both session data from Sessionize exports and speaker information, establishing proper relationships automatically.
Configuration Options
I built flexibility into every aspect of the system:
API Configuration: Switch from mock evaluations to real AI models by setting environment variables:
export GOOGLE_GENERATIVE_AI_API_KEY=your_api_key_hereConcurrency Control: Adjust processing speed based on your API limits:
const queue = fastq.promise(processSession, 2); // Concurrent sessionsCustom Evaluation Criteria: Extend the agent’s output schema to add new scoring dimensions or modify existing ones.
Database Management
The system provides comprehensive database utilities:
# View current processing status
npm run db:view
# Export results in multiple formats
npm run db:export # JSON format
npm run db:export-csv # Spreadsheet-friendly CSV
# Filter exports by status
npm run db:export-filtered Nominated
# Reset for reprocessing
npm run db:resetAdvanced Features and Workflows
Dual Workflow Architecture
One of my key innovations was separating session evaluation from speaker assessment into independent workflows. This modular design offers several advantages:
Session Evaluation Workflow: Focuses purely on content quality, structure, and technical depth Speaker Profile Assessment Workflow: Evaluates speaker credibility, expertise, and conference fit using web scraping
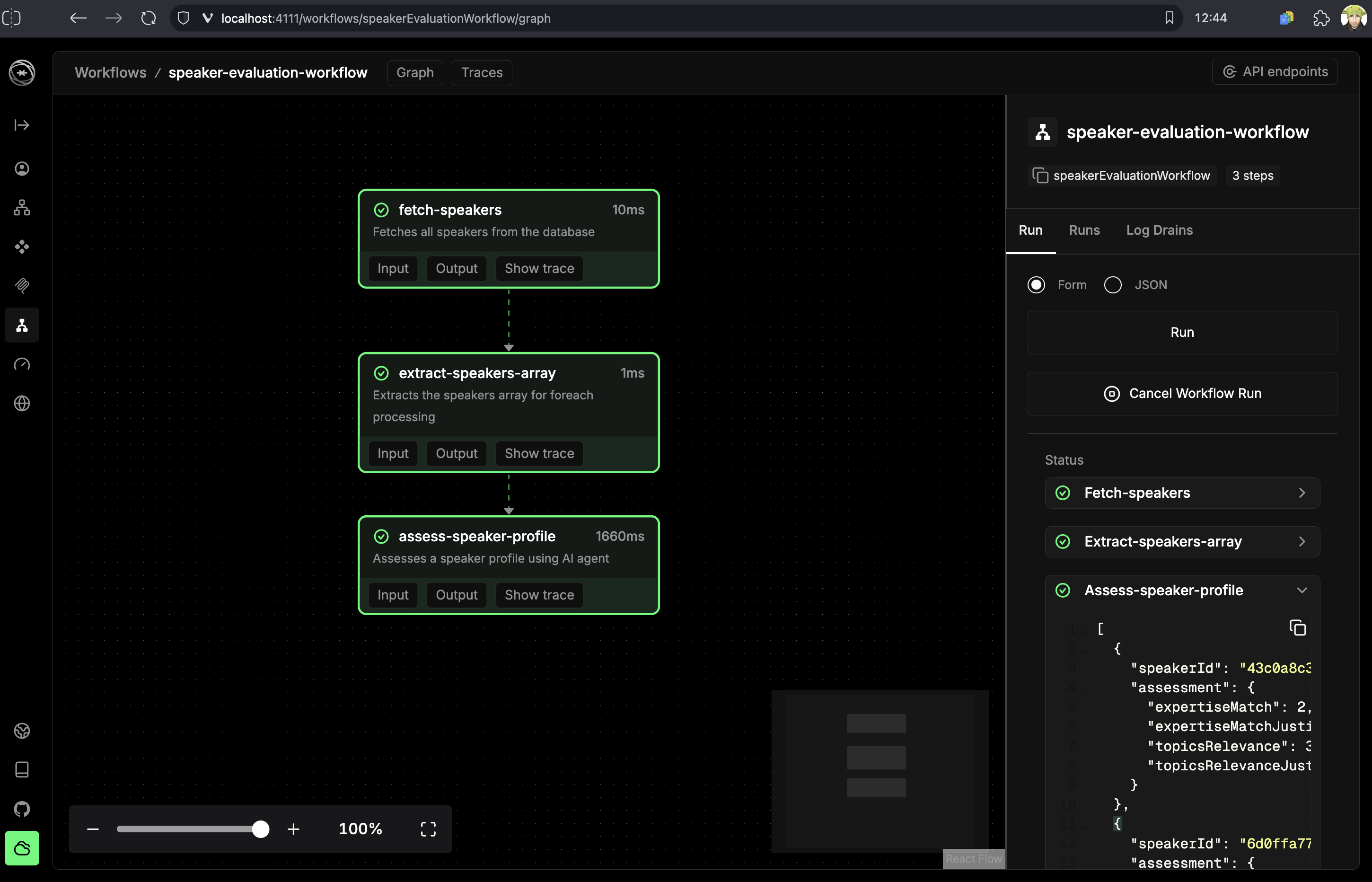
Both workflows can run independently or together, providing maximum flexibility for different evaluation scenarios.
Speaker Profile Evaluation
The speaker assessment workflow showcases the system’s advanced capabilities:
- Database Integration: Fetches all speakers from the SQLite database
- Web Scraping: Uses Playwright to visit Sessionize profiles
- AI Analysis: Evaluates expertise match and topic relevance (1-3 scale)
- Persistent Storage: Saves evaluations with UUID tracking for audit trails
- Concurrency Control: Processes 2 speakers simultaneously to respect rate limits
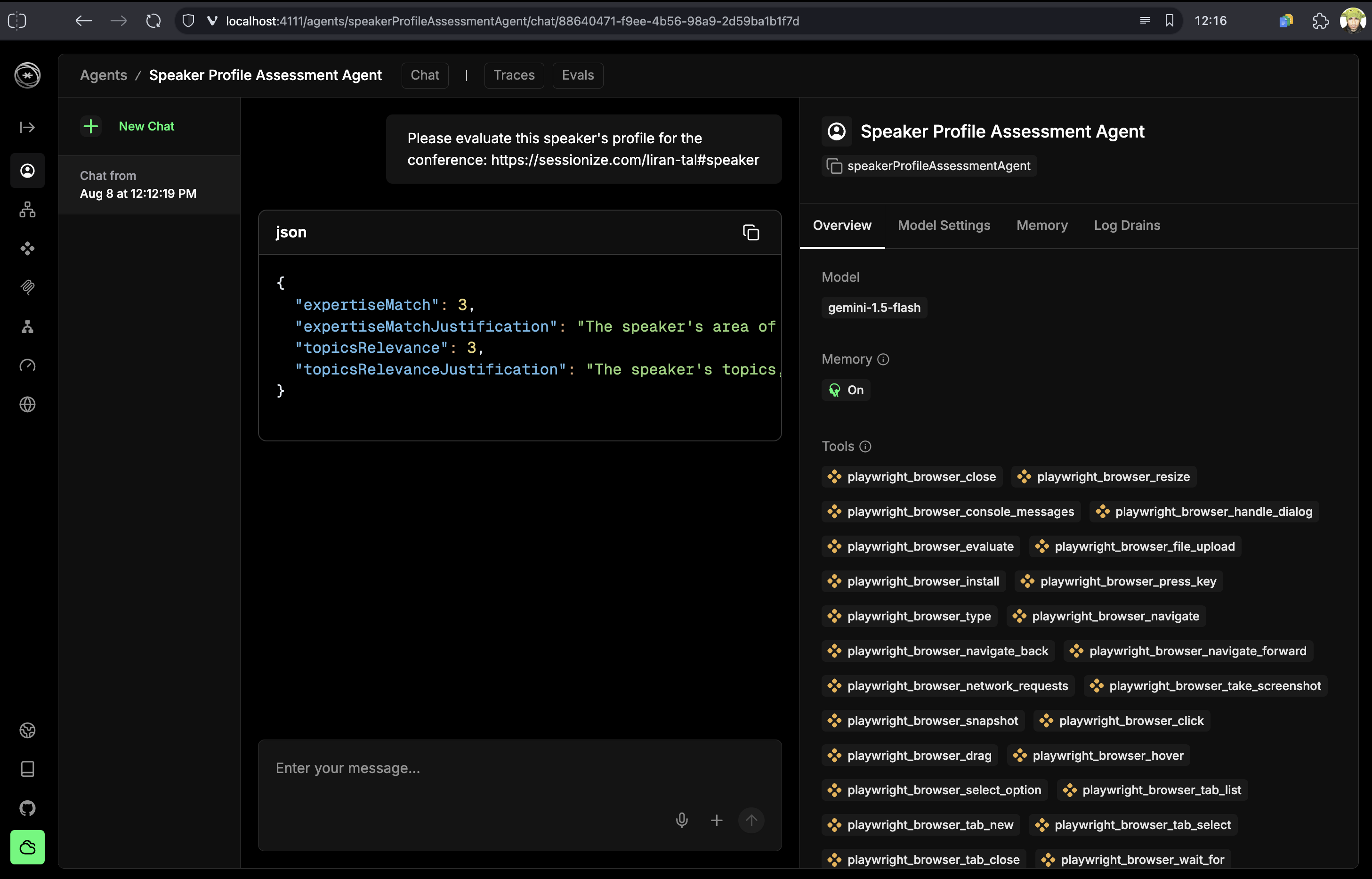
This workflow demonstrates how AI agents can augment human decision-making by gathering and analyzing data that would be impractical to collect manually. The AI provides detailed analysis of each speaker’s background, expertise alignment, and potential conference fit.
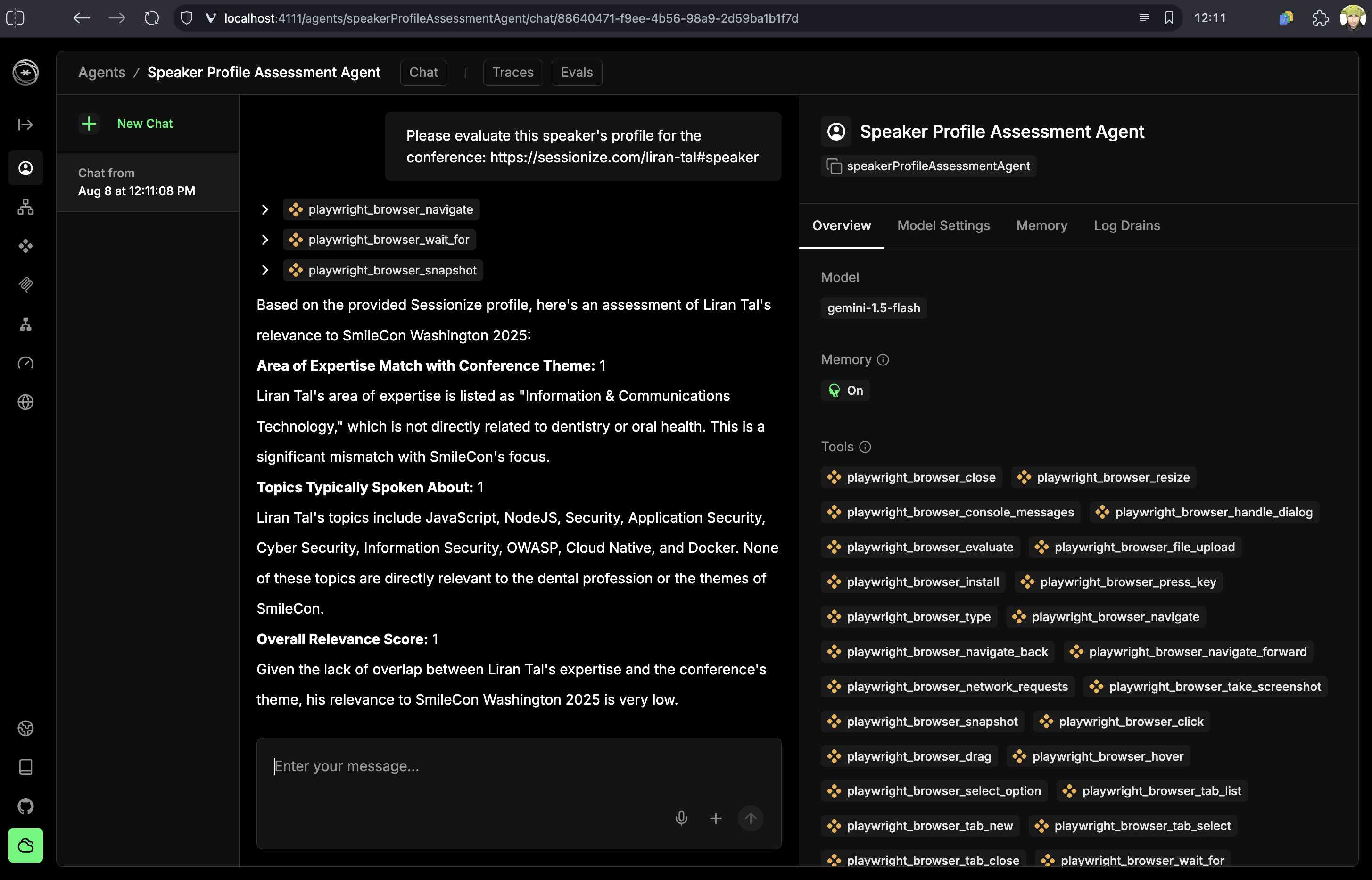
Resume and Recovery Capabilities
I learned the importance of resilience during early testing when API rate limits interrupted long processing runs. The system now includes:
- Status Tracking: Each session maintains processing status (‘new’, ‘ready’)
- Automatic Recovery: Resumes from where it left off after interruptions
- Progress Monitoring: Real-time feedback on processing status
- Error Isolation: Failed sessions don’t affect others in the queue
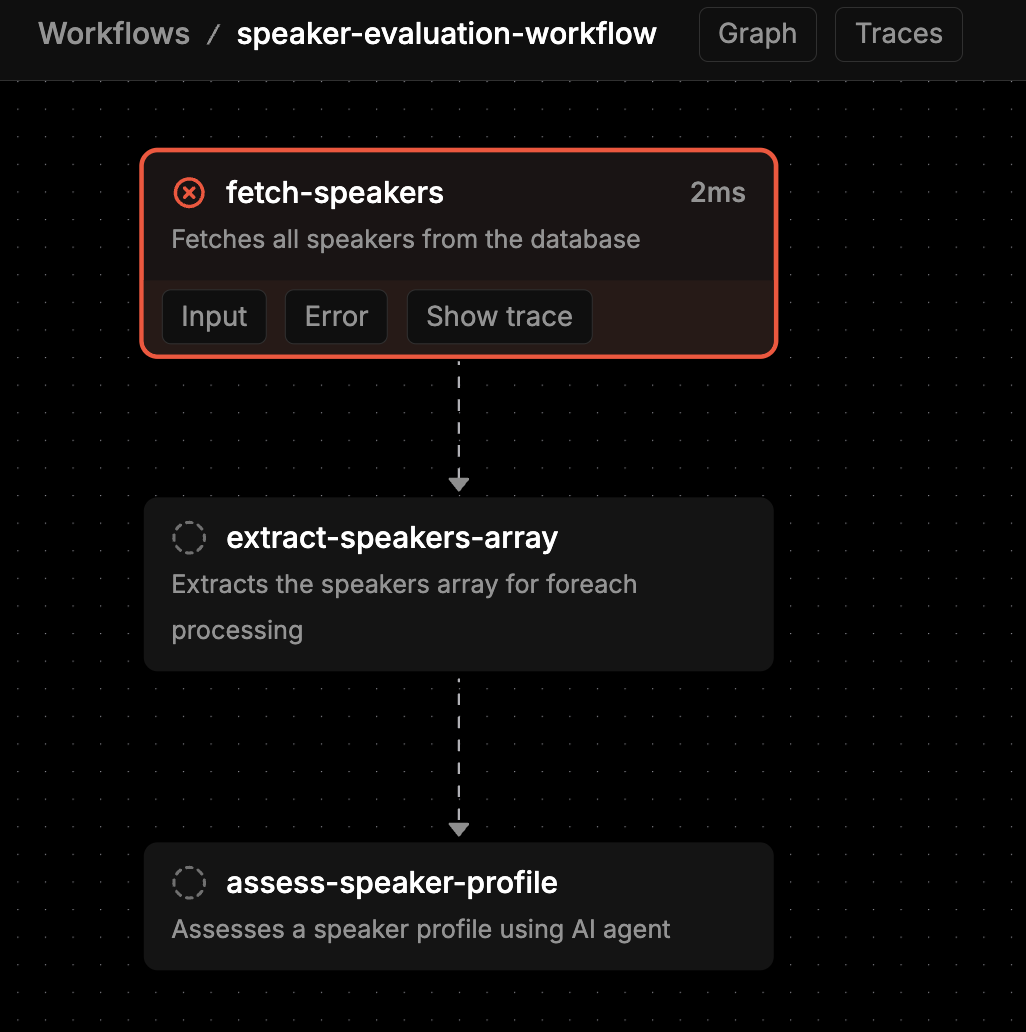
Real-World Use Cases and Impact
Conference Organizers
I’ve seen this system transform conference organizing workflows:
- Multi-track Conferences: Process 300+ submissions across 8 tracks in hours instead of weeks
- Objective Scoring: Eliminate unconscious bias with consistent AI evaluation
- Time Efficiency: Reduce review time from 40+ hours to 2-3 hours of verification
- Quality Consistency: Maintain evaluation standards across multiple reviewers
DevRel Teams
For Developer Relations professionals, the system provides:
- Event Planning Automation: Quickly identify high-potential speakers and topics
- Community Insights: Understand trending topics and speaker expertise
- Resource Optimization: Focus human review time on borderline cases
- Data-Driven Decisions: Make speaker selection based on comprehensive analysis
Educational Value for Developers
Beyond practical applications, this project demonstrates:
- AI Agent Architecture: Real-world implementation of AI workflows using Mastra
- TypeScript Best Practices: Type-safe database operations and API integrations
- Queue Management: Handling concurrent processing with rate limiting
- Data Persistence: Robust SQLite integration with proper schema design
Customization and Extension Opportunities
Adding Custom Evaluation Criteria
The system’s modular design makes it easy to add new evaluation dimensions:
- Update Agent Schema: Modify the output schema in
cfp-evaluation-agent.ts - Extend Database Schema: Add new score fields to the sessions table
- Update Workflow Logic: Include new criteria in the evaluation workflow
- Modify Export Systems: Ensure new fields appear in JSON and CSV exports
Data Source Integration
While I built this for Sessionize data, the architecture supports multiple sources:
- API Endpoints: Replace JSON file loading with direct API integration
- Custom Formats: Adapt the data mapping layer for different CFP platforms
- Real-time Processing: Implement webhook endpoints for live evaluation
- Third-party Services: Integrate with existing conference management tools
Advanced AI Features
Future enhancements I’m considering include:
- Multi-language Support: Evaluate submissions in multiple languages
- Sentiment Analysis: Assess emotional engagement potential
- Plagiarism Detection: Check for duplicate or recycled content
- Market Demand Analysis: Evaluate topic popularity using Google Trends
- Social Proof Integration: Consider speaker social media presence
Benefits and ROI Analysis
Quantifiable Time Savings
Based on my experience organizing conferences:
- Manual Review Time: 3-5 minutes per submission × 300 submissions = 15-25 hours
- Automated Processing: 30 seconds per submission × 300 submissions = 2.5 hours
- Time Savings: 85-90% reduction in initial evaluation time
- Quality Improvement: Consistent application of evaluation criteria
Consistency Advantages
The AI system eliminates common human evaluation issues:
- Fatigue Effects: No degradation in evaluation quality over time
- Bias Reduction: Consistent criteria application regardless of reviewer preferences
- Documentation: Every score includes detailed justification
- Reproducibility: Same evaluation criteria applied to all submissions
Scalability Benefits
The system scales efficiently with submission volume:
- Linear Processing: Processing time scales linearly with submissions
- Concurrent Capability: Multiple evaluations can run simultaneously
- Resource Efficiency: Minimal human oversight required
- Cost Effectiveness: Reduces need for multiple human reviewers
Future Enhancements and Roadmap
Technical Improvements
I’m actively working on several enhancements:
Phase 1: Enhanced AI Integration
- Real-time LLM integration with multiple model support
- Advanced prompt engineering for domain-specific evaluations
- Confidence scoring for AI assessments
Phase 2: Advanced Analytics
- Speaker expertise trending analysis
- Topic clustering and gap identification
- Historical performance correlation analysis
Phase 3: Integration Ecosystem
- Direct Sessionize API integration
- Conference management platform plugins
- Real-time collaboration features for review committees
Community Features
Open Source Collaboration
- Community-driven evaluation criteria
- Shared evaluation datasets for training
- Plugin architecture for custom agents
Transparency Improvements
- Public evaluation methodology documentation
- Open scoring algorithms for community review
- Feedback loops for continuous improvement
How to Run the AI Agent System Locally
1. Environment Preparation
# Ensure Node.js 20.9.0 or later
node --version
# Clone the repository
git clone https://github.com/lirantal/devrel-cfp-committee
cd devrel-cfp-committee2. Dependency Installation
# Install all dependencies
npm install
# Verify Mastra CLI installation
npx mastra --version3. Data Preparation
# Copy your Sessionize exports to the fixtures directory
# Sessions: __fixtures__/db.json
# Speakers: __fixtures__/speakers.json
# Initialize database
npm run db:seed4. Configuration
# For production AI evaluation, set API keys
export GOOGLE_GENERATIVE_AI_API_KEY=your_key_here
# Optional: Configure concurrency limits
# Edit src/app.ts to adjust queue concurrency5. First Evaluation Run
# Process all submissions
npm run process-cfp
# View results
npm run db:view
# Export for analysis
npm run db:export-csvCommon Troubleshooting
Database Path Issues: The system automatically handles Mastra’s execution environment, but if you encounter path errors, ensure the sessions.db file exists in the project root.
API Rate Limits: Start with concurrency set to 1 and gradually increase based on your API provider’s limits.
Memory Usage: For very large datasets (1000+ submissions), monitor memory usage and consider processing in batches.
Best Practices and Tips
Data Quality: Ensure your Sessionize exports include all required fields (title, description, speakers, categories).
Evaluation Criteria: Customize the scoring criteria to match your conference’s specific needs and audience.
Human Review: Use the AI scores as a first-pass filter, then apply human judgment to borderline cases.
Iterative Improvement: Track evaluation accuracy over time and refine prompts based on outcomes.
Conclusion: Transforming Conference Management
Building this AI-powered CFP evaluation system has fundamentally changed how I approach conference organizing. What once required weeks of manual review now takes hours, while maintaining—and often exceeding—the quality and consistency of human evaluation.
The system demonstrates the transformative potential of AI agents when applied thoughtfully to real-world problems. By combining structured evaluation criteria with AI’s ability to process large volumes of data consistently, we can eliminate the drudgery of repetitive tasks while preserving the nuanced judgment that makes great conferences.
More importantly, this project showcases how modern AI frameworks like Mastra enable developers to build production-ready agent systems without requiring deep machine learning expertise. The TypeScript-first approach, combined with robust persistence and resume capabilities, makes this a practical solution for real conference organizing workflows.
As the tech conference landscape continues to grow, tools like this become essential for maintaining quality while scaling operations. The future of conference management lies not in replacing human judgment, but in augmenting it with intelligent systems that handle the heavy lifting while preserving the human insights that make events truly valuable.
Whether you’re a conference organizer seeking to improve your CFP process, a DevRel professional looking to scale event planning, or a developer interested in building practical AI applications, this system provides a comprehensive foundation for intelligent automation in the conference management space.
The code is open source, I invite you to explore, contribute, and help shape the future of AI-powered event management.
Ready to revolutionize your CFP evaluation process? Get started with the repository at https://github.com/lirantal/devrel-cfp-committee and join the community of conference organizers leveraging AI to build better events.
