~ 8 min read
Traits of AI-native Products for Optimized AI Agentic Workflows

As someone who’s been on both ends of application developer and application consumer, it is a fascinating right now to see the shift in computing and how AI is now taking the center stage on both of those ends. Developers use generative AI to write code and at the same time, AI agents are effectively driving application interaction and workflows, on behalf of humans (for now).
So if you’re building applications that are intended to be consumed by AI agents then optimizing for AI-first consumption should be top of mind. But what does it mean?
To allow AI agents to efficiently consume your application and drive workflows around it, we need to distill the essence of what makes an agentic execution successful.
Let’s raise a few questions around how agents execute and try to answer them:
- What are the limiting factors of AI agents? We know that context windows have traditionally been an issue, even if the window keeps increasing with new models, but at the same time, the agentic application utilizes that too for its own benefit and throws a lot of information into the context window of the agent. For example: reading your directory structure, reading source code files, reading recent commits, running an
ast-grepoutput for the context and so much more. - What are the tools available to AI agents? agentic workflows are increasingly transitioning into autonomous execution and LLMs are further expected to invoke tools and MCP servers at their disposal to squeeze the most out of the actionable execution that they can perform. So if AI agents can execute tools, we can leverage that to our advantage.
Let me call it at that with those 2 high level takeaways for now, and continue next to unfold those to actual practices with real-world examples.
AI-first context awareness
As a developer, what artifact can you think of that can quickly deteriorate the quality of a context window and incur a negative performance on the agent execution?
Logs is a first good answer. Another example to point out is large files. Large files are a potential bottleneck for AI agents functioning properly due to the fact that they will eat up a large amount of context window. That could lead to degraded performance because then recent messages become older messages and so on.
Ok so what’s a practical example of this? Imagine you are running a Claude Code agent that works on a code base. As part of the work it needs to run tests. When it runs the tests it runs the entire test suites. Imagine you have a ton of tests and just the output of that test suite, in terms of the test runner or framework (and the reporter) is just excessively large. Every time the agent executes a code change it executes the tests and fills up a large chunk of the context window just for the sake of tests.
$ npm run test
FAIL e2e/__tests__/stackTraceSourceMaps.test.ts (9.807 s)
● processes stack traces and code frames with source maps
Command failed with exit code 1: yarn install --immutable
➤ YN0000: · Yarn 4.9.2
➤ YN0000: ┌ Resolution step
Resolution step
➤ YN0000: └ Completed
➤ YN0000: ┌ Post-resolution validation
Post-resolution validation
➤ YN0000: └ Completed
➤ YN0000: ┌ Fetch step
Fetch step
➤ YN0018: typescript@patch:typescript@npm%3A5.8.3#optional!builtin<compat/typescript>::version=5.8.3&hash=5786d5: The remote archive doesn't match the expected checksum
➤ YN0000: └ Completed in 4s 59ms
➤ YN0000: · Failed with errors in 4s 284ms
{
shortMessage: 'Command failed with exit code 1: yarn install --immutable',
command: 'yarn install --immutable',
escapedCommand: 'yarn install --immutable',
exitCode: 1,
signal: undefined,
signalDescription: undefined,
stdout: '\x1B[94m➤\x1B[39m YN0000: · \x1B[1mYarn 4.9.2\x1B[22m\n' +
'\x1B[94m➤\x1B[39m \x1B[90mYN0000\x1B[39m: ┌ Resolution step\n' +
'::group::Resolution step\n' +
'::endgroup::\n' +
'\x1B[94m➤\x1B[39m \x1B[90mYN0000\x1B[39m: └ Completed\n' +
'\x1B[94m➤\x1B[39m \x1B[90mYN0000\x1B[39m: ┌ Post-resolution validation\n' +
'::group::Post-resolution validation\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mautocomplete-core\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mclient-search\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mautocomplete-core\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;173malgoliasearch\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mautocomplete-plugin-algolia-insights\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mclient-search\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mautocomplete-plugin-algolia-insights\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;173malgoliasearch\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@docsearch/\x1B[39m\x1B[38;5;173mreact\x1B[39m ➤ \x1B[38;5;111mdependencies\x1B[39m ➤ \x1B[38;5;166m@algolia/\x1B[39m\x1B[38;5;173mclient-search\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@react-native/\x1B[39m\x1B[38;5;173mbabel-plugin-codegen\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@babel/\x1B[39m\x1B[38;5;173mpreset-env\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@react-native/\x1B[39m\x1B[38;5;173mbabel-preset\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@babel/\x1B[39m\x1B[38;5;173mpreset-env\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@react-native/\x1B[39m\x1B[38;5;173mcommunity-cli-plugin\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@babel/\x1B[39m\x1B[38;5;173mpreset-env\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;166m@react-native/\x1B[39m\x1B[38;5;173mmetro-babel-transformer\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@babel/\x1B[39m\x1B[38;5;173mpreset-env\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;173mbabel-plugin-transform-flow-enums\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@babel/\x1B[39m\x1B[38;5;173mcore\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'\x1B[93m➤\x1B[39m YN0068: │ \x1B[38;5;173mreact-native\x1B[39m ➤ \x1B[38;5;111mpeerDependencies\x1B[39m ➤ \x1B[38;5;166m@babel/\x1B[39m\x1B[38;5;173mpreset-env\x1B[39m: No matching package in the dependency tree; you may not need this rule anymore.\n' +
'::endgroup::\n' +
'\x1B[94m➤\x1B[39m \x1B[90mYN0000\x1B[39m: └ Completed\n' +
'\x1B[94m➤\x1B[39m \x1B[90mYN0000\x1B[39m: ┌ Fetch step\n' +
'::group::Fetch step\n' +
"\x1B[91m➤\x1B[39m YN0018: │ \x1B[38;5;173mtypescript\x1B[39m\x1B[38;5;111m@\x1B[39m\x1B[38;5;111mpatch:typescript@npm%3A5.8.3#optional!builtin<compat/typescript>::version=5.8.3&hash=5786d5\x1B[39m: The remote archive doesn't match the expected checksum\n" +
'::endgroup::\n' +
"\x1B[91m➤\x1B[39m YN0018: \x1B[38;5;173mtypescript\x1B[39m\x1B[38;5;111m@\x1B[39m\x1B[38;5;111mpatch:typescript@npm%3A5.8.3#optional!builtin<compat/typescript>::version=5.8.3&hash=5786d5\x1B[39m: The remote archive doesn't match the expected checksum\n" +
'\x1B[94m➤\x1B[39m \x1B[90mYN0000\x1B[39m: └ Completed in 4s 59ms\n' +
'\x1B[91m➤\x1B[39m YN0000: · Failed with errors in 4s 284ms',
stderr: '',
failed: true,
timedOut: false,
isCanceled: false,
killed: false
}
// and so on
// more and more test output here ...Oh, you think it is theoretical?
Well then, I invite you to open up the Jest CI for the Node.js sanity, here’s a link directly to the GitHub Action run (if this particular job expires, you can look at another recent run).
Now imagine that the Jest team wanted to embrace agentic coding workflows and unleash Claude Code on their code base. Even simpler use-case, telling Claude Code to look at the logs on the GitHub Action run, investigate why the tests are failing, and fix the code.
So let’s fix it and turn something like:
# This could lead to a situation where the context window is filled with test logs
# and the agent struggles to maintain relevant context for the task at hand.
npm run testInto mitigating it by having tests output a summarized or minimal reported output of the test results, keeping only the necessary context that matters for the agent to continue working on the code base:
# This reduces the amount of context consumed by test logs
npm run test:agentic-summarized -- --reporter=summaryHere is a good example of this from the Bun team, optimizing for AX:
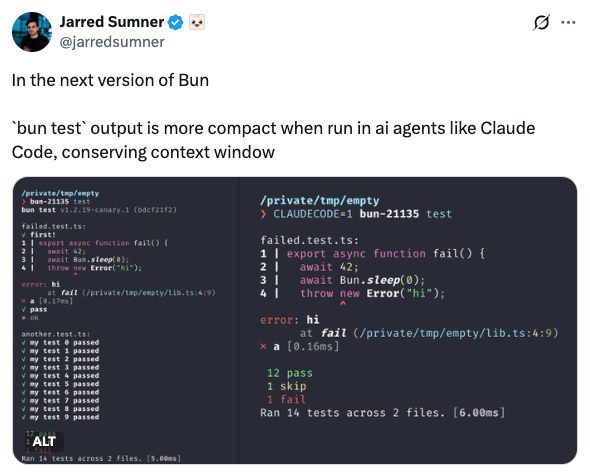
AI-first errors
In a similar way to how we can optimize the context window for AI agents, we can also optimize the agentic execution and its performance by building our applications in a way that provides as much contextual information as necessary to the agent.
Keep in mind that the AI agent may have access to tools and MCP servers. One of those tools may be a browser agent or a general web page fetch tool that allows it to search the web for information.
With that in mind, some overall guidance as follows:
- If the agent can search the web, then you better be clever about your error messages. Instead of a generic error message like
Error: unable to detect input field 'dota'you can use organized error codes such asE273: Input field 'dota' not found in the form 'create-account'. This way, the agent can search forE273and find relevant information about that error code due to search engines indexing it. - Provide dense contextual information in the error message and co-locate important nuances and relevant information to the error. This way, the agent should be able to extract more information without having to rely on the error data scattered at the beginning of the buffer, the end of the buffer and so on.
- Using structured error messages is likely a way to improve the agent’s ability to parse the error and reason about the underlying issue for it to perform root cause analysis and attempt to fix it.
Here is an example of such error message as described above:
Error: E273: Input field 'dota' not found in the form 'create-account'. Please ensure that the input field exists and is correctly named. If the issue persists, refer to the documentation at https://example.com/docs/errors/E273 for troubleshooting steps.